
Rất hiếm khi thấy một bộ xử lý đạt thành công lớn ngoài lĩnh vực mà nó đã dường như đã được mặc định từ trước. Nhưng điều đó đã xảy ra với bộ xử lý đồ họa (GPU – Graphic Processing Unit). Một con chip ban đầu có ý định để tăng tốc đồ họa chơi game. Và bây giờ, nó trở nên rất có uy lực trong mọi thứ từ Adobe Premier, năng lực tính toán cơ sở dữ liệu dành cho máy tính hiệu suất cao (HPC – High Performance Computing) cho đến trí thông minh nhân tạo (AI – Artificial Intelligence).
GPUs hiện được cung cấp bên trong các máy chủ OEM (Original Equipment Manufacturer) , nhưng mục đích chính không phải là để làm tăng tốc đồ họa. Trong trường hợp này, GPU thực chất là một bộ xử lý tính toán khổng lồ, hiện đang được sử dụng để thực hiện công việc tính toán chuyên sâu, từ mô phỏng 3D đến hình ảnh y tế hay các mô hình tài chính phức tạp.
Bởi vì chúng được thiết kế theo xung nhịp đơn, GPU cores nhỏ hơn nhiều so với CPU cores, nên GPU có thể có hàng nghìn lõi trong khi CPU tối đa ở 32. Với tối đa 5.000 lõi có sẵn cho một tác vụ, GPU được thiết kế dành cho các tác vụ cần năng lực xử lý song song rất lớn.
Bất cứ nơi nào một ứng dụng đang cầu xử lý song song, đó là nơi cần đến năng lực xử lý, tính toán của GPU. Trong quá khứ, xử lý song song đã được thực hiện với số lượng lớn các bộ xử lý như x86, vì vậy chúng rất tốn kém và khó lập trình. GPU như một bộ xử lý chuyên dụng cho một mục đích cung cấp mật độ tính toán lớn hơn nhiều, và nó được khai thác trong nhiều nhiệm vụ tăng tốc tối đa năng lực tính toán.
Các ứng dụng cần sự hỗ trợ của GPUs
Việc sử dụng GPU trong trung tâm dữ liệu bắt đầu bằng các ứng dụng nhờ vào ngôn ngữ mà Nvidia phát triển, được gọi là CUDA. CUDA sử dụng cú pháp C/ C++ để gởi yêu cầu đến GPU thay vì CPU, nhưng thay vì gởi yêu cầu một lần, nó có thể gởi hàng ngàn lần song song.
Khi hiệu suất của GPU được cải thiện và các bộ vi xử lý đã chứng tỏ khả thi đối với mọi nhiệm vụ, không chỉ giới hạn trong các xử lý dành cho game, các ứng dụng đóng gói đã bắt đầu xuất hiện và hỗ trợ nhiều hơn cho GPU. Giờ đây, những ứng dụng dành cho máy chủ, bao gồm cả cơ sở dữ liệu SQL cũng đã được xử lý bởi GPU. GPU là lý tưởng để tăng tốc việc xử lý các truy vấn SQL, vì SQL cần thực hiện nhiều thao tác – truy vấn/ định nghĩa/ thao tác/ điều khiển – cùng lúc. GPU có thể thực hiện song song quá trình truy vấn này bằng cách gán nhiều hơn tập truy vấn dữ liệu cho một lõi đơn.
Brytlyt, SQream Technologies, MapD, Kinetica, PG-Strom và Blazegraph đều hỗ trợ tăng tốc GPU trong quá trình phân tích cơ sở dữ liệu của họ. Oracle cho biết họ cũng đang làm việc với Nvidia nhưng đến hiện tại thì chưa có thông tin gì mới. Còn Microsoft hiện không hỗ trợ tăng tốc GPU trên SQL Server.
GPUs và HPC – High Performance Computing
GPU cũng đã gia nhập ngôi nhà HPC, nơi được thiết kể thực hiện nhiều nhiệm vụ chuyên dụng như mô phỏng, mô hình tài chính, dựng hình 3D cũng chạy tốt trong một môi trường song song. Theo Intersect 360, một công ty nghiên cứu thị trường theo thị trường HPC, 34 trong số 50 gói ứng dụng HPC phổ biến nhất cung cấp hỗ trợ GPU, bao gồm tất cả 15 ứng dụng HPC hàng đầu.
“Chúng tôi tin rằng máy tính GPU đã đạt đến điểm bùng phát trong thị trường HPC sẽ khuyến khích tiếp tục tăng trong tối ưu hóa ứng dụng”, các nhà phân tích cho biết trong báo cáo của họ.
Thị trường đang phát triển nhanh chóng cho GPU là trí tuệ nhân tạo (Artificial Intelligence – AI) và máy học (Machine Learning – ML), những thứ mà cần phải xử lý truy vấn song song cực lớn. “Rất nhiều doanh nghiệp và CIO đang xem cách họ có thể sử dụng học tập sâu (Deep Learning – DL) để giải quyết vấn đề của họ. Và giờ đây, đó là công việc của các máy chủ GPU.
Trí tuệ nhân tạo (Artificial Intelligence – AI) làm việc nếu bạn cung cấp đủ mẫu của một vấn đề gì đó cần giải quyết, và bạn muốn vấn đề đó được máy tính giải quyết tốt hơn hoặc thông minh hơn. Hệ thống AI học cách nhận ra một thứ gì đó – giống như những tế bào ung thư trông như thế nào – nhưng để làm như vậy đòi hỏi rất rất nhiều dữ liệu và cần được xử lý liên tục, liên tục để tìm ra các mối tương quan, các điểm chung hoặc tìm ra bất cứ điều gì mà bạn muốn phân tích. Khi các mối tương quan được phát hiện, các thuật toán có thể được tạo ra dẫn đến một phân tích chuẩn xác nhất.
Ví dụ khác, công ty năng lượng Ý Eni và công nghệ Stone Ridge của Mỹ đã có thể xử lý các mô hình dự trữ dầu trong vòng chưa đầy một ngày thay vì mười ngày như trước đây. Họ sử dụng 3.200 GPU NVIDIA Tesla và phần mềm ECHELON của Stone Ridge cho mô phỏng hồ chứa dầu trên GPU, nó xử lý 100.000 mô hình hồ chứa trong khoảng 15 giờ rưỡi, một nhiệm vụ sẽ mất mười ngày sử dụng phần cứng và phần mềm cũ. Mỗi mô hình đơn lẻ mô phỏng 15 năm sản xuất trên trữ lượng đó trong trung bình 28 phút.
Tạo lập được Mô hình hồ chứa dầu không phải là nhiệm vụ đơn giản. Dự trữ được tìm thấy bằng cách dội sóng âm thanh ra khỏi bề mặt Trái Đất và tìm kiếm các tiếng vang cho biết trữ lượng dầu. Sau đó, dữ liệu sóng phản xạ được biến thành hình ảnh mà các nhà địa chất học có thể sử dụng để xác định xem tiềm năng của hồ chứa chứa hydrocacbon và nơi các hydrocacbon nằm trong hình ảnh đã được nạp vào cho AI trước đó. Điều này xác định có đáng hay không để khoan dầu trong khu bảo tồn hoặc một vị trí nhạy cảm nào đó. Tất cả điều này đòi hỏi quá trình xử lý toán học nặng, do GPU đảm nhiệm.
Giống như CPU của Intel, thị trường GPU giảm xuống còn hai người chơi là Nvidia và AMD. Với thị trường game, cả hai cạnh tranh nhau gay gắt với tỷ lệ lần lượt vào khoảng 60 cho Nvidial và 40 cho AMD. Còn trong trung tâm dữ liệu, có thể còn trong tương lai không xa, tỷ lệ này có thể sẽ thay đổi 90% Nvidia và 10% cho AMD.
GPUs và CUDA Programming.
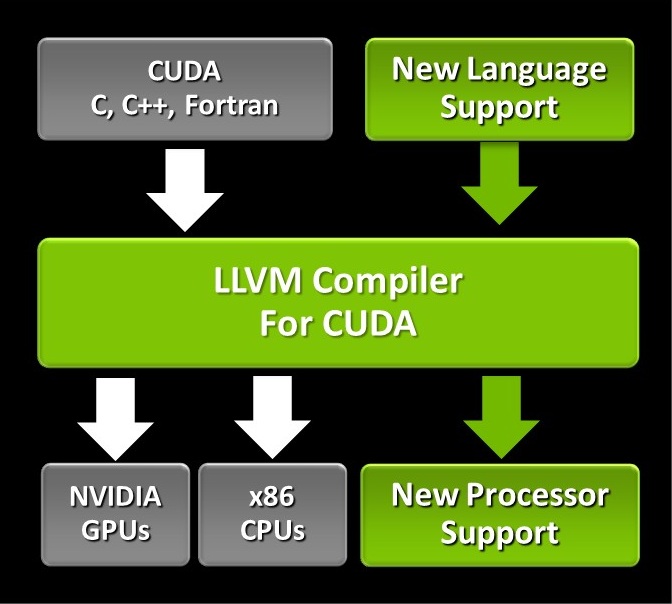
Vào đầu những năm 2000, một số nhà nghiên cứu của Đại học Stanford bắt đầu nghiên cứu kỹ tính chất lập trình song song của GPU. Nvidia thuê họ để tạo ra ngôn ngữ lập trình CUDA cho phép các nhà phát triển viết các ứng dụng bằng C/ C++ sử dụng GPU để tăng tốc.
NVidia đã có những bước đi rất bài bản. Họ thâm nhập vào các trường đại học trên khắp thế giới, hàng trăm người trong số họ, để dạy CUDA. Vì vậy, khi một sinh viên tốt nghiệp, họ là những nhà phát triển CUDA được đào tạo trước và đặt nền tảng cho việc đưa CUDA vào các ngành như chúng ta biết ngày nay.
Một trong những giáo sư Stanford thuộc nhóm CUDA là Ian Buck, hiện là phó chủ tịch bộ phận kinh doanh máy tính chuyên về tốc độ (Nvidia’s Accelerated Computing) của Nvidia. Ông nói rằng CUDA được dự định là dễ học và sử dụng. “Bất cứ ai biết C hay Fortran, tôi có thể dạy CUAD trong một ngày. Chúng tôi đã sớm nhận ra rằng chúng tôi không muốn tạo ra một ngôn ngữ lập trình hoàn toàn mới yêu cầu bạn phải học một điều gì đó mới mẻ ”, ông nói.
Hiện tại, các ứng dụng chạy trên CPU có thể được xử lý song song tương đối nhanh chóng. Nhưng, thay đổi chính với CUDA là thay vì gọi một hàm một lần, giống như một thói quen sắp xếp, bạn gọi nó hàng ngàn lần cho mỗi lõi thực hiện nó song song. Đáng tiếc là CUDA thì chỉ dành cho GPU Nvidia. Để lập trình một GPU AMD, bạn phải sử dụng một thư viện có tên OpenCL.
GPU là một lựa chọn thay thế mạnh mẽ cho CPU trong vấn đề hiệu suất. Và có một liên kết trực tiếp giữa hiệu suất và năng lượng tiêu thụ. GPU có công suất tối đa 300 watt. Một CPU trung bình trong khoản 100 watt, mặc dù thế hệ Skylake mới của Xeons có thể lên trên 200 watt.
Cuối cùng thì các GPU tạo nên lợi thế dựa vào tính co dãn của chúng. Có thể bạn sẽ phải mất hàng chục CPU để xử lý một công việc nào đó, trong khi bạn sẽ chỉ cần số GPU ít hơn rất nhiều. Nvidia cho biết các hệ thống máy chủ GPU DGX-2 đạt hiệu suất 1/18 sức mạnh của một cụm HPC CPU truyền thống để thực hiện công việc tương tự.
(Bài viết tham khảo thông tin từ Internet)